Introduction#
Preamble#
The data analysis process is a series of steps that are used to organize, clean, and analyze data. The process is used to extract useful information from the data and to make decisions based on the data. The process is used in a variety of fields, including business, science, and engineering. The process is typically broken down into several steps, including data collection, data cleaning, data analysis, and data visualization.
The scope of this notebook is to provide a brief introduction to the data analysis process using the Python programming language and the Pandas library (https://pandas.pydata.org/). Pandas is a powerful data manipulation library for Python that provides data structures and functions for working with structured data. It also provides basic tools for data visualization, but the use of more powerful libraries like Matplotlib or Seaborn is recommended for more complex visualizations.
For data manipulation, we make the choice to work with Pandas; other libraries like NumPy, SciPy, and Scikit-learn are also commonly used for data analysis.
Objectives#
in this notebook, we will cover the following topics:
Data Laoding
Data Manipulation
Data Visualization
Data Analysis / data modeling
We will use as example data set a list of students with their grades in different tests.
First of all, let’s have a look at the data set#
For that you need to open the data set in is native format, in this case a csv file. csv files are text files that store data in a tabular format, with each row representing a record and each column representing a field. Therefore, you can open the file with a text editor or a spreadsheet software like Excel.
Required files
The data set is available in the _DATA folder attached to this notebook.
warning
Open the data with Excel might change the format of the data, so it is recommended to use a text editor like Notepad++ or Visual Studio Code.
df = pd.read_csv("./_DATA/Note_csv.csv", delimiter=";")
df
| section | TD | name | ET | CC | |
|---|---|---|---|---|---|
| 0 | MM | A | ami | 14.50 | 11.75 |
| 1 | MM | A | joyce | 8.50 | 11.50 |
| 2 | MM | C | lola | 9.50 | 13.25 |
| 3 | MM | B | irma | 7.50 | 6.00 |
| 4 | IAI | D | florence | 14.50 | 13.25 |
| ... | ... | ... | ... | ... | ... |
| 90 | MM | A | james | 13.75 | 12.75 |
| 91 | IAI | D | richard | 15.25 | 7.00 |
| 92 | MM | A | caprice | 18.25 | 15.00 |
| 93 | IAI | D | al | 12.50 | 9.75 |
| 94 | MM | B | constance | 3.00 | 7.00 |
95 rows × 5 columns
Data Loading and basic manipulation#
Load data and create a data frame from csv file#
More explanation can be found here : https://chrisalbon.com/python/data_wrangling/pandas_dataframe_importing_csv/
Display the dataframe#
# return the beginning of the dataframe
df.head()
| section | TD | name | ET | CC | |
|---|---|---|---|---|---|
| 0 | MM | A | ami | 14.5 | 11.75 |
| 1 | MM | A | joyce | 8.5 | 11.50 |
| 2 | MM | C | lola | 9.5 | 13.25 |
| 3 | MM | B | irma | 7.5 | 6.00 |
| 4 | IAI | D | florence | 14.5 | 13.25 |
# return the end of the dataframe
df.tail(10)
| section | TD | name | ET | CC | |
|---|---|---|---|---|---|
| 85 | MM | A | vin | 11.00 | 13.00 |
| 86 | MM | A | jeunesse | 12.00 | 10.50 |
| 87 | MM | A | victoire | 11.75 | 12.00 |
| 88 | MM | B | joseph | 8.00 | 10.00 |
| 89 | MM | A | fꭩx | 13.00 | 14.50 |
| 90 | MM | A | james | 13.75 | 12.75 |
| 91 | IAI | D | richard | 15.25 | 7.00 |
| 92 | MM | A | caprice | 18.25 | 15.00 |
| 93 | IAI | D | al | 12.50 | 9.75 |
| 94 | MM | B | constance | 3.00 | 7.00 |
Selecting data in a dataframe#
# get data from index 2
df.loc[2]
section MM
TD C
name lola
ET 9.5
CC 13.25
Name: 2, dtype: object
# get name from index 2
0.7 * df.ET + 0.3 * df.CC
0 13.675
1 9.400
2 10.625
3 7.050
4 14.125
...
90 13.450
91 12.775
92 17.275
93 11.675
94 4.200
Length: 95, dtype: float64
# Sliccing is also working
df.name[6]
'brian'
Get one of row of the dataframe#
df.TD
0 A
1 A
2 C
3 B
4 D
..
90 A
91 D
92 A
93 D
94 B
Name: TD, Length: 95, dtype: str
df.sort_values("ET")
| section | TD | name | ET | CC | |
|---|---|---|---|---|---|
| 71 | IAI | C | platon | 1.00 | 7.25 |
| 94 | MM | B | constance | 3.00 | 7.00 |
| 60 | IAI | D | bꢴrice | 3.25 | 8.00 |
| 74 | IAI | D | bob | 4.50 | 5.00 |
| 21 | IAI | D | lasse | 4.50 | 8.50 |
| ... | ... | ... | ... | ... | ... |
| 16 | MM | C | louis | 17.50 | 15.50 |
| 68 | IAI | D | ursula | 17.75 | 13.00 |
| 92 | MM | A | caprice | 18.25 | 15.00 |
| 32 | IAI | D | dora | NaN | 2.00 |
| 33 | IAI | D | violet | NaN | 0.25 |
95 rows × 5 columns
Start to do some basic analysis and visualization#
Get the number of students in each group.#
df.TD.value_counts()
TD
B 25
A 24
C 23
D 23
Name: count, dtype: int64
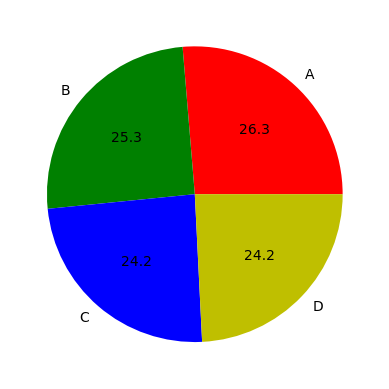
Get the proportion of students between groups#
df.TD.value_counts(normalize=True)
TD
B 0.263158
A 0.252632
C 0.242105
D 0.242105
Name: proportion, dtype: float64
Display the proportion of students between groups#
Using the plot function of panda:
visualization option of pandas can be found here : http://pandas.pydata.org/pandas-docs/version/0.18/visualization.html
fig = plt.figure()
df.TD.value_counts(normalize=True).plot.pie(
labels=["A", "B", "C", "D"], colors=["r", "g", "b", "y"], autopct="%.1f"
)
plt.show()
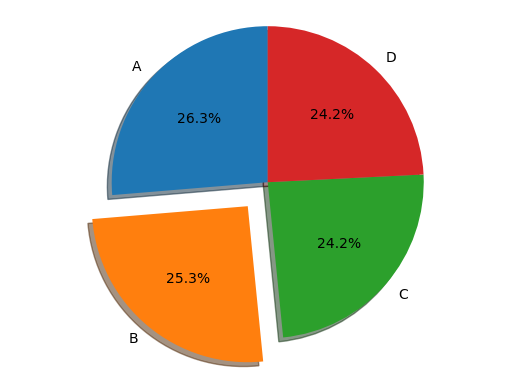
Using the plot function of matplotlib:
val = df.TD.value_counts(normalize=True).values
explode = (0.0, 0.2, 0.0, 0)
labels = "A", "B", "C", "D"
fig1, ax1 = plt.subplots()
ax1.pie(
val, explode=explode, labels=labels, autopct="%1.1f%%", shadow=True, startangle=90
)
ax1.axis("equal") # Equal aspect ratio ensures that pie is drawn as a circle.
plt.show()
Get student list who get a grad higher than 14/20 on both ET and CC#
df[(df.ET > 15.0) & (df.CC < 10.0)]
| section | TD | name | ET | CC | |
|---|---|---|---|---|---|
| 35 | IAI | D | achille | 17.50 | 9.5 |
| 91 | IAI | D | richard | 15.25 | 7.0 |
df[(df.ET > 14.0) & (df.CC > 14.0)]
| section | TD | name | ET | CC | |
|---|---|---|---|---|---|
| 7 | MM | B | antoinette | 14.50 | 17.0 |
| 16 | MM | C | louis | 17.50 | 15.5 |
| 77 | MM | C | karl | 14.50 | 17.5 |
| 81 | MM | B | mari | 15.00 | 15.0 |
| 82 | IAI | C | rose | 17.50 | 15.0 |
| 92 | MM | A | caprice | 18.25 | 15.0 |
Make Calculation on Data#
The mean of ET grads over all students#
df.ET.mean()
np.float64(11.043010752688172)
The mean of ET over students from B group#
df[df.TD == "A"].ET.mean()
df[df.TD == "B"].ET.mean()
df[df.TD == "C"].ET.mean()
df[df.TD == "D"].ET.mean()
np.float64(11.345238095238095)
Statistical description of the data by TD using the ‘groupby()’ function#
df.groupby(["section"]).ET.mean() # compte the mean of each note for each groupe
section
IAI 10.804688
MM 11.168033
Name: ET, dtype: float64
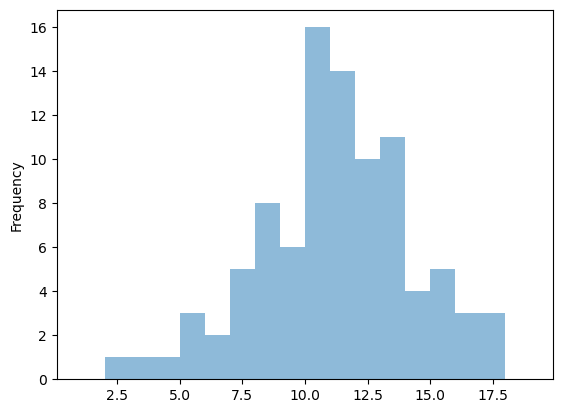
Display the grads with a histogram plot#
# CC notes
fig = plt.figure()
df.CC.plot.hist(alpha=0.5, bins=np.arange(1, 20))
plt.show()
# ET notes
fig = plt.figure()
df.ET.plot.hist(alpha=0.5, bins=np.arange(1, 20))
plt.show()
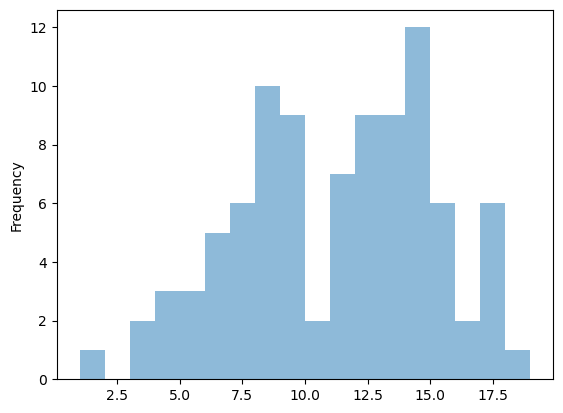
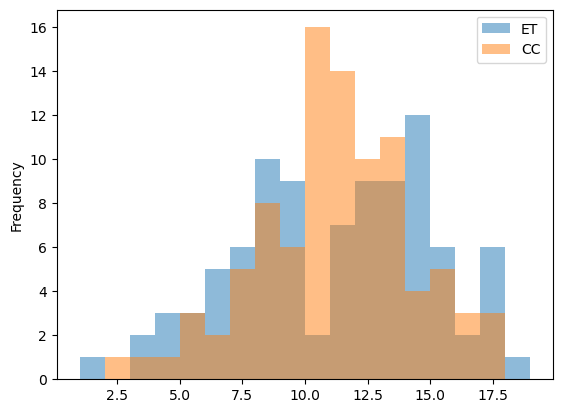
fig = plt.figure()
df.plot.hist(alpha=0.5, bins=np.arange(1, 20))
plt.show()
<Figure size 640x480 with 0 Axes>
Let’s compute the mean of both grads#
We need first to add a new row to a data frame#
df["FinalNote"] = 0.0 # add row filled with 0.0
df
| section | TD | name | ET | CC | FinalNote | |
|---|---|---|---|---|---|---|
| 0 | MM | A | ami | 14.50 | 11.75 | 0.0 |
| 1 | MM | A | joyce | 8.50 | 11.50 | 0.0 |
| 2 | MM | C | lola | 9.50 | 13.25 | 0.0 |
| 3 | MM | B | irma | 7.50 | 6.00 | 0.0 |
| 4 | IAI | D | florence | 14.50 | 13.25 | 0.0 |
| ... | ... | ... | ... | ... | ... | ... |
| 90 | MM | A | james | 13.75 | 12.75 | 0.0 |
| 91 | IAI | D | richard | 15.25 | 7.00 | 0.0 |
| 92 | MM | A | caprice | 18.25 | 15.00 | 0.0 |
| 93 | IAI | D | al | 12.50 | 9.75 | 0.0 |
| 94 | MM | B | constance | 3.00 | 7.00 | 0.0 |
95 rows × 6 columns
df.head()
| section | TD | name | ET | CC | FinalNote | |
|---|---|---|---|---|---|---|
| 0 | MM | A | ami | 14.5 | 11.75 | 0.0 |
| 1 | MM | A | joyce | 8.5 | 11.50 | 0.0 |
| 2 | MM | C | lola | 9.5 | 13.25 | 0.0 |
| 3 | MM | B | irma | 7.5 | 6.00 | 0.0 |
| 4 | IAI | D | florence | 14.5 | 13.25 | 0.0 |
Let’s compute the mean#
df["FinalNote"] = 0.7 * df.ET + 0.3 * df.CC
# the axis option alows comptuting the mean over lines or rows
df.head()
| section | TD | name | ET | CC | FinalNote | |
|---|---|---|---|---|---|---|
| 0 | MM | A | ami | 14.5 | 11.75 | 13.675 |
| 1 | MM | A | joyce | 8.5 | 11.50 | 9.400 |
| 2 | MM | C | lola | 9.5 | 13.25 | 10.625 |
| 3 | MM | B | irma | 7.5 | 6.00 | 7.050 |
| 4 | IAI | D | florence | 14.5 | 13.25 | 14.125 |
df.to_csv("res.csv")
fig = plt.figure()
df.FinalNote.plot.hist(alpha=0.5, bins=np.arange(1, 20))
plt.show()
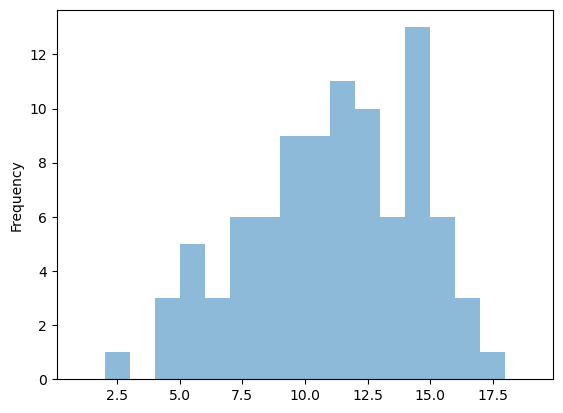
What is the overall mean ?#
df.FinalNote.mean()
np.float64(11.08695652173913)